Commute Burden
Context
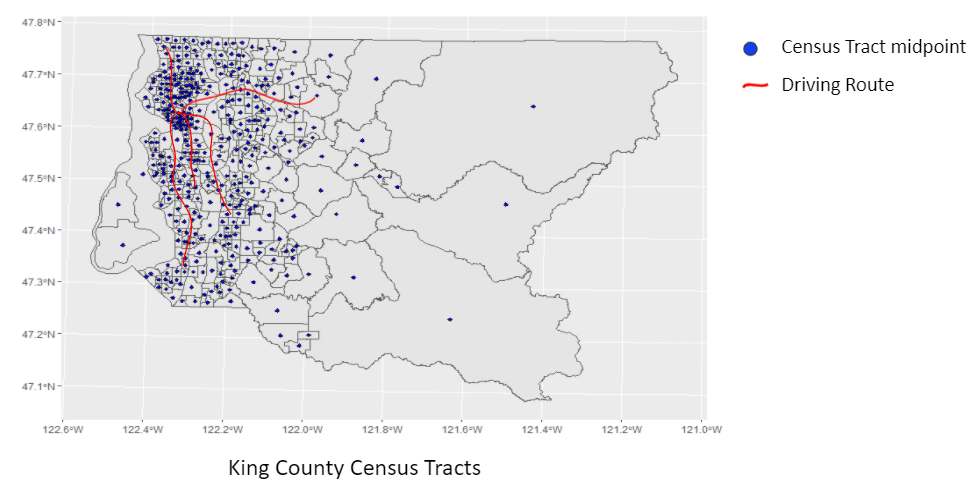
One possible way of assessing an individual’s spatial mismatch, is by tracking their commuting changes over time. Particularly, estimating their distance traveled and time spent commuting can determine if their commute burden is improving or worsening. To do this, we can utilize the geocoded data from WMLAD that contains a person’s residential and work address. However, even though the WMLAD archivists have gone to great lengths to de-identify individuals, a person can still be identified using home and work locations along with other spatial indicators. For this reason, we have decided to further de-identify individuals by analyzing commute variables at the census tract level. That is, a person’s home and work location will only be tied to some arbitrary census tract midpoint. This is demonstrated in the figure below that exemplifies King County census tracts, their associated midpoints, and example commutes from home tract midpoints to work tract midpoints.
Preparing Data
The data preparation builds from our definition of low-wage workers as well as similar data merging outlined in the residential displacement section. This results in merging data from the Employment Security Department, which contains information such as work location, wages, and hours worked, with any other agency that contains residential address. This merged dataset provides starting and ending geographic coordinates (at the census tract level) that can be used to calculate commuting distance and time. We elected to use an open sourced mapping tool called graphhopper to calculate these distances. For clarity, our analysis did not consider public transportation commuting times due to limitations of the grapphoper tool. Code for some of the routines using graphhoper can be found on our github repository.
Visualizations
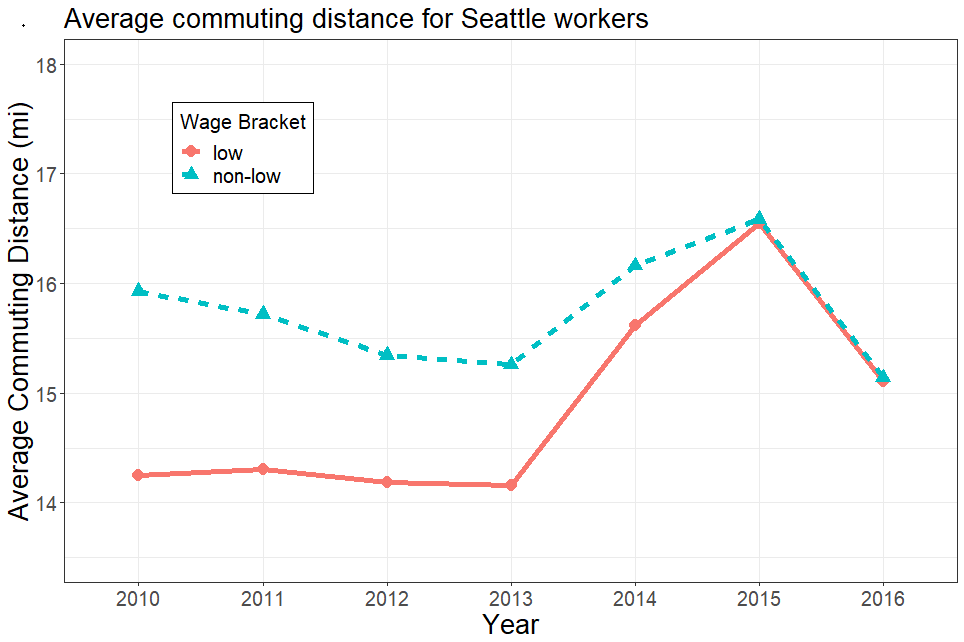
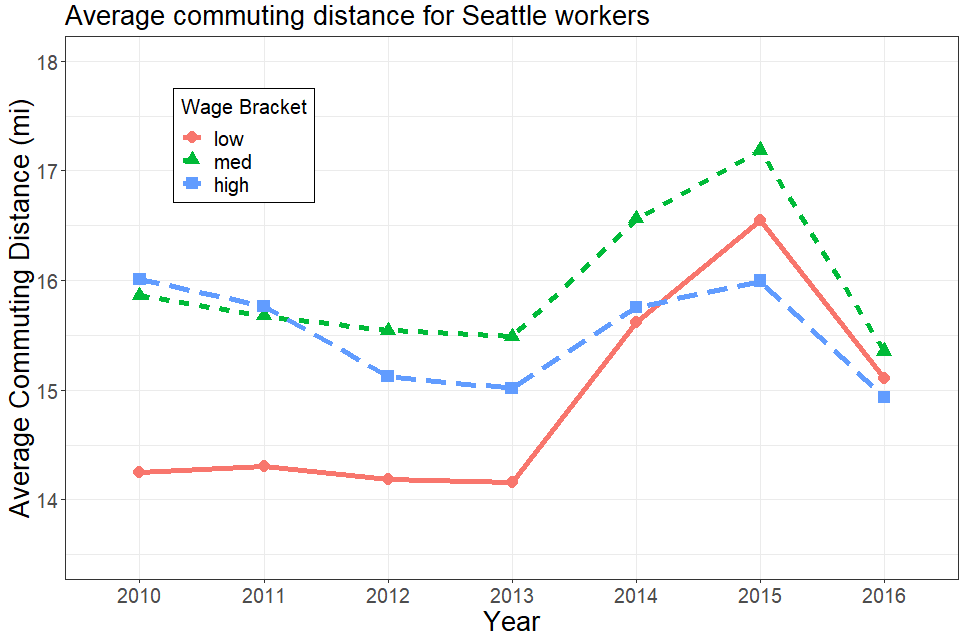
Below are initial investigations of average commuting distances for differing wage brackets. This is to demonstrate that the results of an analysis may depend on a certain level of granularity for variables of interest.